Elevate Credit, an alternative credit provider that lends to customers currently underserved by mainstream finances, requires a robust data science team and industry-leading technology stack to originate more than $4.9 billion in credit to more than 1.8 million non-prime customers in the UK and US1. The company is outspoken on its dedication to advanced analytical techniques as a means to comply with regulatory responsibilities and to benefit its growing customer base.
Because Elevate sets itself apart with its data driven approach—it’s not uncommon for Elevate to use thousands of different facts in the process of underwriting a new customer—we knew we had to speak with one of the forward-thinking data scientists in Elevate’s Risk Management department. John Bartley has over ten years of experience in financial services and recently oversaw an effort to transition Elevate’s UK’s credit risk models from SAS to R. You will definitely hear more about that in this interview.
Adi: John, thank you for taking the time to speak with us about Elevate’s impressive data science initiatives. Can you give us an overview of your recent work with Elevate?
John: Thank you, Adi. Absolutely. Of course, we’re excited about the recently launched Elevate Labs at our Advanced Analytics Center in San Diego, California. Elevate has always been committed to innovating the world of data science in credit risk, so this facility is just the next step in that constant evolution. It is a pleasure to work with the high caliber talent we’re able to attract because of that commitment.
On the day-to-day, we’re focused on continually improving our analytical models to serve the non-prime market in the US and high-cost short-term credit market in the UK. For example, we have observed huge uplift in one of our acquisition Channels in the UK as a result of improvements in our modeling. The better that our models are able to explain and predict consumer behaviour, the more of the alternative credit market we’re able to address.
A: What types of data is Elevate using in its underwriting process?
J: Our risk analytics stack utilizes a terabyte-scale Hadoop infrastructure composed of thousands of elements, customer records, and other wide-ranging data inputs including credit bureau data, web behavioral and performance data, bank transaction data and other non-traditional data. All of this works to give us a holistic view of the customer and helps us accurately assign risk to those applications.
Advanced machine learning techniques let us consider these factors in the development of algorithms which better predict behaviour and customer vulnerability. Actually, we recently moved to R because of the range of modeling techniques R is able to support. Using appropriate modeling techniques has allowed us to significantly simplify our underwriting and lead to more accurate predictions of likely loan performance.
Also read: What is credit underwriting?
A: What prompted the adoption of R?
Before moving to R, we used SAS to develop pretty sophisticated credit risk models. SAS has traditionally been the software of choice for many statisticians and credit risk professionals working in the banking and financial services sector and although SAS is good for many applications in this sector, we find that it is far less flexible when compared to an open source programming language like R.
To provide an example, a far more complex credit risk strategy (e.g. population segmentation) was required to get our historic linear model’s to provide the necessary lift to adequately underwrite a population. This is because many consumers in the high-cost short-term credit market have complex and varied credit histories. At Elevate, our goal is to provide our customers with a comparable experience to prime lending. In order to do this, we need to use tools (such as R) that allow us to build more complex models to adequately understand the complex financial histories of our consumers.
R has a number of packages for powerful machine learning algorithms such as RandomForest and XGBoost. While SAS does support some of these modeling techniques we have found it is far quicker to build, and implement some of the newer techniques using R. In my experience, R also provides better support for multi-threading which often helps us to train our models in far shorter periods of time. In addition, the range of algorithms SAS has developed which utilize their high performance technology is limited in comparison to the options I have when considering a modeling challenge using R.
And, of course, you know we deploy our models through your platform. Provenir gives us the capability we need to test and operationalize our advanced analytical models so we can make strategic changes quickly. So, we felt comfortable making big modeling changes from that perspective.
See how simple it is to deploy R and Python models in Provenir with this insider how-to:
A: Moving away from linear models, what techniques are you currently focusing on?
Linear models have been used extensively in credit risk because they are relatively simple to construct and easy to understand. However, given the limitations of some credit risk models that we discussed and the complexity of our datasets, we now utilize a combination of both linear and nonlinear modeling techniques.
A: Are you interested in throwing your experience into the linear vs. nonlinear discussion?
Sure. In a situation where there is a simple linear relationship between predictors and outcomes, linear models work very well. However, linear models have many limitations because they often struggle with complexity and nonlinear relationships.
A linear model may look like this:
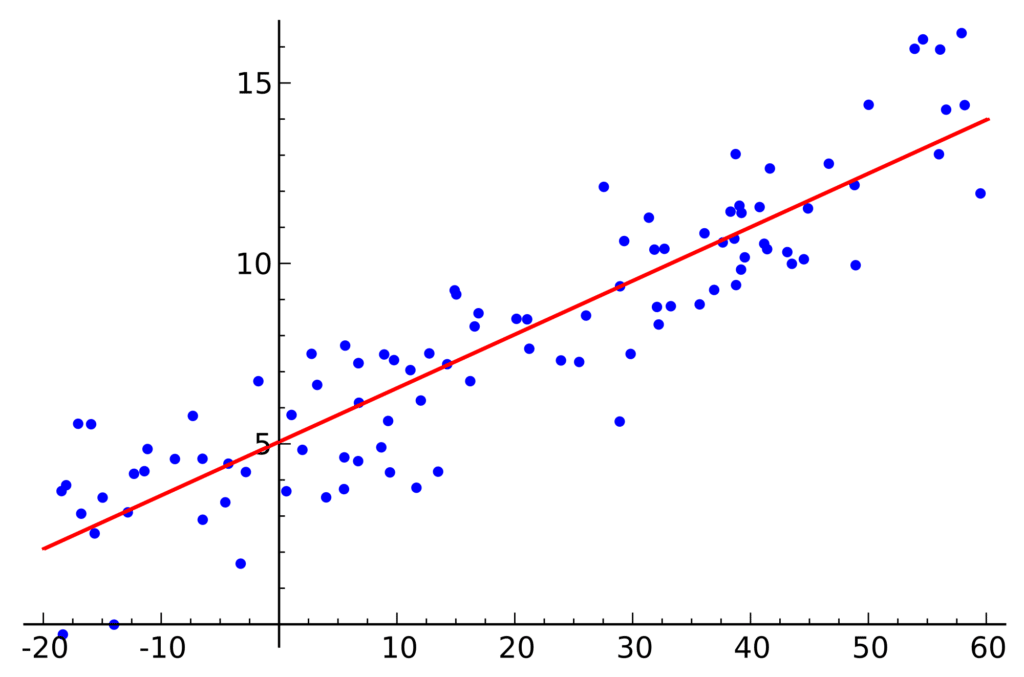
Image source:
https://upload.wikimedia.org/wikipedia/commons/thumb/3/3a/Linear_regression.svg/2000px-Linear_regression.svg.png
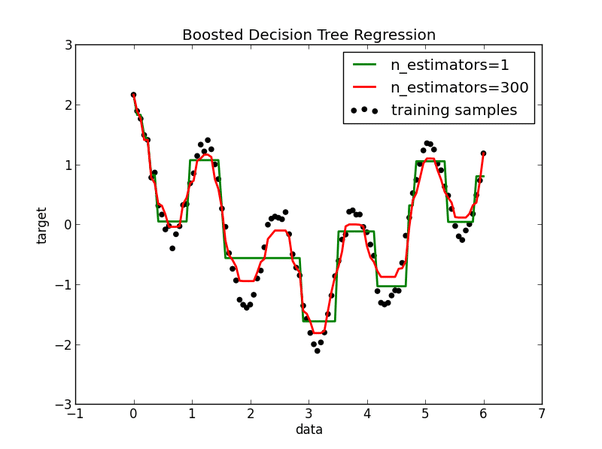
The correlation between the predicted and actual outcome of a tree-based model on a complex non-linear dataset may look something like this.
By contrast, a tree-based model does a much better job at approximating the complexity of the dataset.
Tree-based models afford many advantages. For example, tree-based models are quite good at mapping non-linear relationships which simply can’t be modeled by linear regression. Tree-based models are typically highly-accurate, very stable but can be more difficult to explain.
(To note: It is important to consider that tree-based models contain built-in segmentation when using boosting and bagging techniques.)
With complex data sources where different segments may exhibit very different behaviour (holding everything else constant), a tree-based model is often better at predicting an outcome. Utilizing tree-based models in conjunction with including more characteristics has helped us to significantly improve our customer underwriting.
A: Wow. So, you’ve presumably improved the accuracy of your models, how has that impacted the business strategy challenges you mentioned?
Using a combination of both linear and nonlinear modeling techniques gives us the flexibility to significantly simplify our business strategy. For example, with our new machine learning models, we only need to have a handful of strategies in place. We get a simplified strategy and model that is more adept at explaining different types of people some of which we weren’t able to underwrite before.
A: Have you seen an uplift in approval rates since you deployed this new R model in production?
Although it is still too early to tell, initial results indicate that our new model is performing significantly better than the prior model. We’ve seen an increase in our approval rates and as our recently underwritten vintages continue to develop over, we continue to dial up performance. Obviously that has significant implications for our customers. At Elevate, we feel strongly about helping our customers find financial relief and as we improve our modeling, we improve our ability to serve a population which is underserved by mainstream finance.
A: Changing direction a little bit, I have one last question before you go. You have an impressive history in data sciences and financial services. What are your thoughts on the future of data science in this industry?
Much has changed in analysis and data science in the last 10 years. Statisticians and data scientists have always worked to predict the probability of default, but the techniques that statisticians and data scientists use have evolved significantly.
Ten years ago, for example, nonlinear models were challenging because many organizations didn’t have the computational power or technical skills in place to effectively use these advanced techniques. Fast forward ten years and that has completely changed. This movement toward nonlinear models provides better accuracy while empowering a simplified risk strategy.
That’s where the future begins. Now that the industry has begun to accept more complex modeling techniques it is in a better position to accept non-conventional data sources.
Currently, most organizations have both summaries and tradeline variables from Bureaus. Many in the industry are very reliant on summary variables, though there is a trend toward using tradeline variables. That’s where the next big change is: It’s not just around modeling techniques, but around data sources. I believe we will see the need to bring in different and more granular data sources.
As capacity expands, there will be more emphasis placed on non-traditional variables, which is something we already do at Elevate. Organizations will want to be able to analyze things such as an individuals’ bank transactions, especially for thin bureau file applications, to allow them to decision an application with varying data sources.
A: John, thank you for taking the time to share your expertise today. Looking forward to speaking again soon.
J: Cheers!
About John
John Bartley is a Data Scientist at Elevate at Elevates offices in London, UK. John has over 10 years’ experience as an analyst and data scientist predominantly in the banking and financial services sector.