Giampaolo Levorato, Senior Data Scientist, Provenir & Dr. Mark Thackham, Head of Data Science, Provenir
Wie man Erklärbarkeit und Transparenz bei komplexen ML-Modellen erreicht
Immer mehr Kreditgeber setzen fortschrittliche Machine Learning (ML)-Modelle ein, um Kreditbewertungen und -entscheidungen zu treffen. ML-Modelle (wie Random Forest, XGBoost, LightGBM und Neural Networks) sind prädiktiver und genauer als der Industriestandard Logistische Regression, da sie hochkomplexe, nichtlineare Beziehungen erfassen. Ohne sorgfältige Konfiguration während des Trainings können jedoch sowohl die Erklärbarkeit als auch die Generalisierung des Modells beeinträchtigt werden. Dies ist deshalb so wichtig, weil die Kreditentscheidungsmodelle zwei Kriterien erfüllen müssen:
- Erklärbarkeit: Die Modellvariablen sind für die Nutzer transparent und liefern nachvollziehbare Schlussfolgerungen für Kunden, deren Kreditantrag abgelehnt wurde.
- Generalisierung: Die Modelle sind nicht überangepasst an die Trainingsdaten und zeigen gute Leistungen bei neuen (Produktions-)Daten.
In diesem Artikel wird erläutert, wie wichtig es ist, beim Training von ML-Modellen sowohl monotone Beschränkungen als auch Interaktionsbeschränkungen (monotonic and interaction constraints) anzuwenden, um diese Kriterien zu erfüllen.
Transparenz und Handlungsfähigkeit
In vielen Ländern müssen die Kreditgeber erklären, wie und warum sie einen Kreditantrag abgelehnt haben.Sie müssen die Hauptgründe für die Ablehnung in Form von „Adverse Action Codes“ angeben. Korrekte Erklärungen, warum die Vorhersage eines Modells einen Kreditgeber dazu veranlasst hat, einen Kredit abzulehnen, machen die ML-Modelle transparent (es gibt keine Unklarheiten („Blackbox“) hinsichtlich der Gründe für die Vorhersage des Modells) und umsetzbar (der Kunde, dessen Kredit abgelehnt wurde, hat klare und greifbare Maßnahmen, die er ergreifen kann, um seine Aussichten auf einen neuen Kredit zu verbessern). Konkretes Beispiel für die Erklärbarkeit: Wenn das Merkmal eines Modells, das sich am negativsten auf einen abgelehnten Kreditantragsteller auswirkt, die „Anzahl der Bonitätsabfragen in den letzten sechs Monaten“ ist, könnte der Adverse Action Code lauten: „Die Anzahl der Bonitätsabfragen in den letzten sechs Monaten ist zu hoch.“ Dadurch wird der Hauptgrund transparent, und dem Kunden wird verdeutlicht, dass er seine Kreditanträge reduzieren muss, um seine Kreditwürdigkeit zu verbessern. Die abgelehnten Antragsteller können sich leichter der Gründe bewusst werden, die eine bessere Bewertung verhindern, und ihre Kreditwürdigkeit verbessern.
Die Transparenz gibt den Kreditgebern die Sicherheit, dass Kreditentscheidungen auf erklärbaren und vertretbaren Merkmalen beruhen und nicht auf geschützten Merkmalen wie Geschlecht, Religion oder ethnischer Herkunft.
Es gibt viele Erklärungsmethoden, die bei der Interpretation von Einflussfaktoren komplexer Modelle helfen, aber zwei davon erfreuen sich zunehmender Beliebtheit:
- Local Interpretable Model-Agnostic Explanations (LIME)
- SHapley Additive exPlanation (SHAP)
LIME nutzt zur Vereinfachung komplexer ML-Modelle ein leichter zu erklärendes lokales Modell. Da LIME ein Proxy-Modell verwendet, das sich auf die lokalen Auswirkungen der Merkmale konzentriert, kann es nicht für die Generierung von Adverse Action Codes verwendet werden, die speziell mit dem für die Kreditentscheidung verwendeten ML-Modell (und nicht mit einem Proxy) generiert werden müssen.
SHAP quantifiziert den Beitrag jedes Merkmals zu einer von einem ML-Modell getroffenen Vorhersage (Merkmale mit größeren Beiträgen zur Modellvorhersage haben einen größeren SHAP) und macht so Modellvorhersagen transparent. Die Transparenz, die sich aus der Anwendung von SHAP-Werten ergibt, führt jedoch nicht direkt zu der für die Verwendung von Adverse Action Codes erforderlichen Handlungsfähigkeit. Um SHAP-Werte bei der Ableitung von Adverse Action Codes zu verwenden, sind die folgenden Trainingsbedingungen erforderlich:
- monotonic interaction constraints
- interaction monotonic constraints.
Warum sind Modellbeschränkungen notwendig?
Um zu verstehen, warum solche Beschränkungen des Modells erforderlich sind, ist es nützlich, sich ein SHAP-Abhängigkeitsdiagramm anzuschauen, das die Auswirkungen eines einzelnen Merkmals auf die Vorhersagen des Modells zeigt (das nachstehende Diagramm wurde anhand eines Gradient-Boosting-Entscheidungsbaums erstellt, der auf einem Kreditrisikodatensatz mit dem Ziel trainiert wurde, die Ausfallwahrscheinlichkeit von Kreditantragstellern zu schätzen).
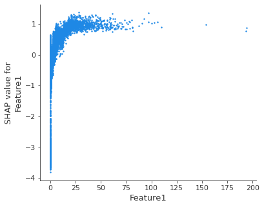
Bild 1 – SHAP-Abhängigkeitsdiagramm für Merkmal1
Die erste Erkenntnis ist, dass das Muster nicht monoton ist: Wenn die Merkmal1-Werte steigen, verbessert sich die Kreditwürdigkeit, bis schließlich eine Verschlechterung vorhergesagt wird.
Die erste Maßnahme, die erforderlich ist, ist die Durchsetzung monotoner Beschränkungen, die die Modellvorhersagen in Bezug auf ein Merkmal monoton ansteigen oder abfallen lassen, während alle anderen Merkmale unverändert bleiben. Im obigen Beispiel würden höhere Werte bei Merkmal1 einer besseren Kreditwürdigkeit entsprechen. Abweichungen von der Monotonie (die häufig auftreten, wenn monotone Merkmalsbeschränkungen nicht angewendet werden) stellen selten ein echtes Muster dar, sondern können auf eine Überanpassung der Beziehung in der Stichprobe hinweisen, wodurch die Modellgeneralisierung verringert wird.
Die Anwendung monotoner Beschränkungen reicht nicht aus, um aus den SHAP-Werten Adverse Action Codes abzuleiten. Tatsächlich können Merkmale bis zu einem gewissen Grad miteinander korreliert sein: Wenn Merkmale in einem ML-Modell miteinander interagieren, kann die Vorhersage nicht als Summe der Merkmalseffekte ausgedrückt werden, da die Wirkung eines Merkmals vom Wert einiger anderer abhängt. Das folgende SHAP-Abhängigkeitsdiagramm zeigt, wie die Wirkung von Merkmal1 abhängig ist von der Wirkung von Merkmal2: Die Interaktion zwischen Merkmal1 und Merkmal2 zeigt sich als ein ausgeprägtes vertikales Muster der Färbung.
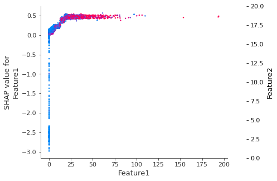
Bild 2 – SHAP-Abhängigkeitsdiagramm zeigt die Interaktion zwischen Merkmal1 und Merkmal2
Die zweite Maßnahme, die ergriffen werden muss, ist die Durchsetzung von Interaktionsbeschränkungen, die es ermöglichen, das Verhalten jedes einzelnen Merkmals unabhängig von allen anderen Merkmalen zu isolieren, so dass man sich ein klares Bild davon machen kann, wie ein einzelnes Merkmal ein Risiko vorhersagt: Eine Modellvorhersage entspricht also der Summe aller Einzelwirkungen.
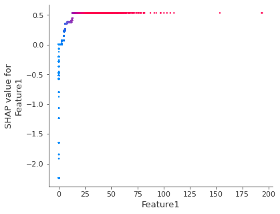
Wenn sowohl monotone Beschränkungen als auch Interaktionsbeschränkungen angewandt werden, können SHAP-Werte verwendet werden, um Adverse Action Codes abzuleiten (zu den weiteren Vorteilen gehören schnellere Trainingsprozesse, bessere Modellgeneralisierung und eine einfacher zu interpretierende Merkmalsgewichtung). Das folgende SHAP-Abhängigkeitsdiagramm zeigt die Auswirkung von Merkmal1 auf die Modellvorhersage, nachdem beide Beschränkungenangewendet wurden: Es ist zu erkennen, dass eine monotone, Eins-zu-eins-Beziehung zwischen den Merkmalswerten und den SHAP-Werten besteht.
Bild 3 – SHAP-Abhängigkeitsdiagramm von Merkmal 1 nach Anwendung von monotonen und Interaktionsbeschränkungen
Mit Provenir KI Compliance gewährleisten
Provenir KI verfolgt einen gezielten Ansatz bei der Entwicklung von ML-Modellen, indem es dafür sorgt, dass Überanpassungen vermieden und vollständig transparente und umsetzbare Modelle bereitgestellt werden. Dies begünstigt den Zugang der Verbraucher zu Finanzierungen und ermöglicht es den Kreditgebern gleichzeitig, die Finanzvorschriften einzuhalten.