Giampaolo Levorato, Senior Data Scientist, Provenir & Dr. Mark Thackham, Head of Data Science, Provenir
Cómo lograr explicabilidad y transparencia con modelos complejos de aprendizaje automatizado (ML)
Una cantidad cada vez mayor de prestamistas está adoptando modelos de Aprendizaje Automatizado (Machine Learning, ML) para alimentar información al proceso de toma de decisiones crediticias. Los modelos ML (como Random Forest, XGBoost, LightGBM y Neural Networks) tienen una capacidad predictiva y de precisión que supera el estándar de la industria de Regresión logística, ya que permiten capturar relaciones no lineales altamente complejas. No obstante, sin una configuración meticulosa durante la capacitación, tanto la explicabilidad como la generalización del modelo pueden verse afectadas. Este aspecto resulta esencial porque los modelos de toma de decisiones crediticias deben cumplir con un criterio doble de:
- Explicabilidad: los impulsores del modelo son transparentes para los usuarios y proporcionan conclusiones ejecutables para los clientes a quienes se les ha denegado crédito.
- Generalización: los modelos no sobreajustan los datos de capacitación y se desempeñan correctamente con datos (de producción) nuevos.
Este artículo explica la importancia de aplicar limitaciones tanto monotónicas como de interacción cuando se capacitan los modelos ML a fin de cumplir con estos criterios.
Transparencia y posibilidad de ejecución
Muchas jurisdicciones exigen que los prestamistas expliquen cómo y por qué han denegado una solicitud de crédito, estipulando que los prestamistas proporcionen Códigos de acción adversa que indiquen las razones principales por las que se denegó el crédito. Las explicaciones correctas por las que la predicción de un modelo lleva a un prestamista a denegar una solicitud de crédito convierten a los modelos ML en transparentes (no existe una ambigüedad de “caja negra” relacionada con los impulsores de la predicción del modelo) y ejecutables (el crédito denegado al cliente está acompañado de medidas claras y tangibles que puede tomar el solicitante para mejorar su probabilidad de obtener un crédito). En un ejemplo concreto de explicabilidad, si la característica de un modelo con el impacto más negativo para el solicitante al que se le ha denegado un préstamo es “la cantidad de consultas crediticias realizadas en los últimos seis meses”, el Código de acción adversa podríaser “la cantidad de consultas crediticias de los últimos seis meses es demasiado alta”. Esta cualidad ofrece transparencia con respecto al impulsor principal y una acción clara para los clientes que indica que para mejorar su solvencia, es necesario que reduzcan la cantidad de consultas crediticias. De esta manera, es más sencillo para los solicitantes conocer los factores que evitan que alcancen calificaciones superiores y mejoren su solvencia.
La transparencia además les garantiza a los prestamistas que las decisiones crediticias se basen en motivos posibles de explicar y defender, y no en atributos protegidos tales como género, religión o etnia.
Existen numerosos métodos de explicabilidad que ayudan a interpretar los impulsores de modelos complejos, pero dos de ellos han cobrado popularidad:
- Explicaciones de Modelo Agnóstico Local Interpretable (Local Interpretable Model-Agnostic, LIME)
- Explicaciones Aditivas de SHapley (SHapley Additive exPlanation, SHAP)
LIME aproxima modelos ML complejos con un modelo local más simple que es más sencillo de explicar. Como LIME utiliza un modelo proxy que se concentra en el impacto local de las características, no puede utilizarse para generar Códigos de acción adversa, los cuales deben obtenerse específicamente usando el modelo ML adoptado para la toma de decisiones crediticias (y no un proxy).
SHAPcuantifica la contribución de cada característica a una predicción que efectúa el modelo ML (las características que tienen mayor incidencia en la predicción del modelo tienen un SHAP mayor), lo cual transparenta las predicciones del modelo. Pero la transparencia basada en el uso de valores SHAP no da lugar directamente a la posibilidad de ejecución que es necesaria para utilizar en Códigos de acción adversa. Para poder usar valores SHAP en la obtención de códigos de acción adversa, se necesitan las siguientes limitaciones de capacitación:
- limitaciones de interacción monotónica, y
- limitaciones monotónicas de interacción.
¿Por qué son necesarias las limitaciones al modelo?
Para entender el motivo por el cual se requieren tales limitaciones al modelo, resulta útil observar un diagrama de dependencia de SHAP que muestra el efecto que tiene una sola característica en las predicciones que efectúa el modelo (el siguiente gráfico se obtuvo a partir de un árbol de decisión de potenciación del gradiente, el cual se capacitó con un conjunto de datos de riesgo crediticio con el objetivo de estimar la probabilidad de insolvencia de distintos solicitantes de crédito).
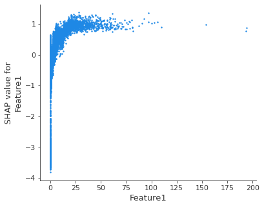
Figura 1 – Diagrama de dependencia de SHAP para la Característica1
La primera observación es que el patrón es no monotónico: a medida que los valores de la Caracterísitca1 aumentan, también lo hace la solvencia, hasta el punto previsto de deterioro.
La primera acción que se necesita es imponer las limitaciones monotónicas, las cuales aumentan o reducen monotónicamente las predicciones del modelo con respecto a una característica cuando todas las demás características se mantienen sin cambio. En el ejemplo anterior, los valores más altos de la Característica1 corresponderían a una solvencia superior. Las desviaciones de la monotonicidad (que pueden ocurrir con frecuencia cuando no se aplican las limitaciones monotónicas a la característica) raramente representan un patrón genuino; más bien pueden indicar un sobreajuste de la relación dentro de la muestra, reduciendo así la generalización del modelo.
La aplicación de limitaciones monotónicas no es suficiente para utilizar los valores SHAP para obtener Códigos de acción adversa. De hecho, puede existir una correlación entre las características en cierta medida: cuando las características interactúan unas con otras en un modelo ML, la predicción no puede expresarse como la suma de los efectos de las características, debido a que el efecto de una característica depende del valor de otras.
El siguiente diagrama de dependencia de SHAP muestra la manera en que la Característica1 depende del efecto de la Característica2: la interacción entre la Caracterísitica1 y la Característica2 aparece como un patrón vertical evidente de color.
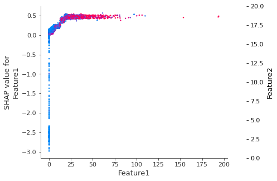
Figura 2 – El diagrama de dependencia de SHAP muestra la interacción entre la Característica1 y la Característica2
La segunda acción que debe tomarse es imponer las limitaciones de interacción, lo que le permite al modelo aislar el comportamiento de cada características de manera independiente de las demás características, haciendo posible obtener una imagen clara de la forma en que una característica individual predice el riesgo: como resultado, una predicción del modelo se corresponde con la suma de cada efecto individual.
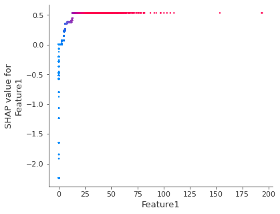
Cuando se aplican ambos tipos de limitaciones, monotónicas y de interacción, los valores SHAP pueden usarse para obtener Códigos de acción adversa (algunos beneficios adicionales incluyen procesos de capacitación más veloces, una mejor generalización del modelo y una mayor facilidad para interpretar los cálculos de importancia de las características). El siguiente diagrama de dependencia de SHAP muestra el efecto de la Característica1 en la predicción del modelo después de que se aplican ambos tipos de limitaciones: puede observarse que existe una relación uno a uno monotónica entre los valores de las características y los valores SHAP.
Figura 3 – Diagrama de dependencia de SHAP de la Característica 1 después de aplicar las limitaciones monotónicas y de interacción.
Cumplimiento con la IA de Provenir
La IA de Provenir adopta un enfoque metódico con respecto al desarrollo de modelos ML al garantizar que se evite el sobreajuste y al crear modelos totalmente transparentes y ejecutables, lo cual favorece el acceso de los clientes al financiamiento y, al mismo tiempo, permite a los prestamistas cumplir con las regulaciones financieras.