Giampaolo Levorato, Senior Data Scientist, Provenir & Dr. Mark Thackham, Head of Data Science, Provenir
Como obter explicabilidade e transparência com modelos complexos de ML
Um número cada vez maior de financiadores tem adotado modelos avançados de aprendizagem de máquina (ML) para decisões de crédito. Os modelos de ML (como Random Forest, XGBoost, LightGBM e redes neurais) são mais preditivos e precisos quando comparados à regressão logística utilizada como padrão em análises de crédito tendo em vista sua capacidade de capturar relações não lineares altamente complexas. Sem uma configuração cuidadosa durante o treinamento, contudo, tanto a explicabilidade quanto o poder de generalização do modelo podem ser afetados. Isso é crucial, uma vez que os modelos de decisão de crédito devem atender a dois critérios:
- Explicabilidade: os mecanismos do modelo devem ser transparentes para os usuários e prover conclusões acionáveis para clientes com crédito recusado; e
- Generalização: os modelos não devem sobreajustar os dados de treinamento e devem apresentar um alto poder de generalização, i.e., devem alcançar alta performance em novos dados (de produção).
Este artigo explica a importância de se aplicar restrições monotônicas e de interação ao treinar modelos de ML a fim de atender a esses critérios.
Transparência e acionabilidade
Muitas jurisdições exigem que os financiadores expliquem como e por que uma solicitação de crédito foi recusada, estipulando que os financiadores forneçam códigos de ação adversa com os principais motivos da recusa. Explicações corretas sobre por que a previsão de um modelo levou um financiador a recusar o crédito torna os modelos de ML transparentes (não há a imprecisão de uma “caixa preta” quanto aos mecanismos de previsão do modelo) e acionáveis (o crédito recusado do cliente tem ações claras e tangíveis sobre as medidas que podem ser tomadas para melhorar suas perspectivas de obter crédito). Vejamos um exemplo concreto de explicabilidade: se o atributo em um modelo cujo impacto mais negativo para quem tem crédito recusado for o “número de buscas de crédito nos últimos seis meses”, então o código de ação adversa poderiaser “o número de buscas de crédito nos últimos seis meses é muito alto”. Isso mostra transparência e indica uma ação clara para os clientes que, para melhorarem sua credibilidade, precisam reduzir suas buscas de crédito. Assim, os solicitantes podem se conscientizar mais facilmente dos fatores que os impedem de ter melhores pontuações e melhorar sua credibilidade.
A transparência garante ainda aos financiadores que as decisões de crédito sejam baseadas em atributos explicáveis e defensáveis e não usem atributos protegidos por lei como sexo, religião ou etnia.
Há diversos métodos de explicabilidade para interpretar decisões de modelos complexos. Dois dos mais populares são:
- Local Interpretable Model-Agnostic Explanations (LIME)
- SHapley Additive exPlanation (SHAP)
O LIME aproxima modelos complexos de ML com um modelo local mais simples e fácil de explicar. Como o LIME utiliza um modelo proxy com foco no impacto local dos atributos, não se pode empregá-lo na geração de códigos de ação adversa, os quais devem ser gerados com o modelo de ML adotado para decisão de crédito (e não um proxy).
O SHAPquantifica a contribuição de cada atributo para uma previsão feita por um modelo de ML (atributos com maiores contribuições para a previsão do modelo têm um SHAP superior), tornando as previsões do modelo transparentes. Todavia, a transparência não leva diretamente à ação necessária para uso em códigos de ação adversa. Para usar os valores SHAP na derivação de códigos de ação adversa é necessário impor as seguintes restrições ao treinamento do modelo:
- restrições de não-interação e
- restrições de monotonicidade.
Por que as restrições do modelo são necessárias?
Para entender a necessidade de tais restrições, é útil observar um gráfico de dependência SHAP que mostra o efeito de um único atributo nas previsões feitas pelo modelo (o gráfico abaixo foi produzido a partir de uma árvore de decisão com gradient boosting treinada em um conjunto de dados de risco de crédito com o objetivo de estimar a probabilidade de inadimplência dos solicitantes de empréstimos).
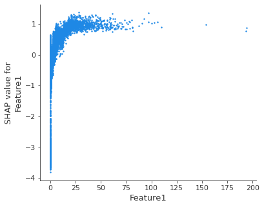
Figura 1 – Gráfico de dependência SHAP para o Atributo 1
A primeira observação é que o padrão é não monotônico: à medida que os valores do Atributo 1 aumentam, a qualidade de crédito melhora, até que se preveja uma deterioração.
A primeira ação necessária é aplicar restrições de monotonicidade, que impõem previsões de modelo para aumentar ou diminuir monotonicamente em relação a um atributo quando todos os outros atributos permanecem inalterados. No exemplo acima, valores mais altos do Atributo 1 correspondem a mais qualidade de crédito. Desvios da monotonicidade (que podem ocorrer frequentemente quando as restrições de atributos monotônicos não são aplicadas) raramente representam um padrão genuíno, e sim geralmente indicam um sobreajuste excessivo aos dados de treino, comprometendo o poder de generalização do modelo.
A aplicação de restrições de monotonicidade não é suficiente para que os valores SHAP retornem códigos de ação adversa. De fato, os atributos podem ser correlacionados até certo ponto: quando os recursos interagem entre si em um modelo de ML, a previsão não pode ser expressa como a soma dos efeitos dos atributos, porque o efeito de um atributo depende do valor de outros.
O gráfico de dependência SHAP a seguir mostra como o efeito de Atributo 1 depende do Atributo 2: a interação entre ambos aparece como um padrão vertical distinto de coloração.
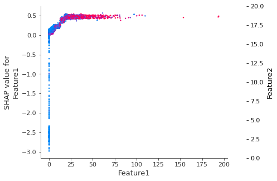
Figura 2 – Gráfico de dependência SHAP mostrando interação entre Atributo 1 e Atributo 2
A segunda ação que precisa ser tomada é impor restrições de não-interação, que permitem isolar o comportamento do modelo em relação a cada atributo independente de todos os outros atributos, fornecendo uma imagem clara de como um atributo individual prediz o risco. Assim, a previsão do modelo corresponde à soma de cada efeito individual.
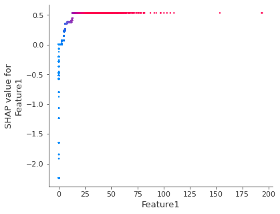
Quando as restrições de monotonicidade e denão-interação são aplicadas, os valores SHAP podem ser usados para retornar códigos de ação adversa (alguns benefícios adicionais são processos de treinamento mais rápidos, maior poder de generalização do modelo e cálculos de importância de atributos mais fáceis de interpretar). O gráfico de dependência SHAP a seguir mostra o efeito do Atributo 1 na previsão do modelo após a aplicação de ambas as restrições: pode-se notar que há uma relação monotônica de um para um entre os valores do atributo e os valores SHAP.
Figura 3 – Gráfico de dependência SHAP do Atributo 1 depois com restrições monotônicas e de interação aplicadas
Mantenha a conformidade com o Provenir AI
O Provenir AI adota uma abordagem cuidadosa para o desenvolvimento do modelo de ML, prevenindo o sobreajuste e fornecendo modelos totalmente transparentes e acionáveis, favorecendo o acesso dos consumidores ao financiamento e, simultaneamente, permitindo que os financiadores cumpram as regulamentações financeiras.