Giampaolo Levorato, Senior Data Scientist, Provenir & Dr. Mark Thackham, Head of Data Science, Provenir
How to achieve explainability and transparency with complex ML models
An ever-increasing number of lenders are adopting advanced Machine Learning (ML) models to inform credit decisions. ML models (such as Random Forest, XGBoost, LightGBM and Neural Networks) are more predictive and accurate than the industry standard Logistic Regression, as they capture highly complex nonlinear relationships. However, without careful configuration during training, both model explainability and generalization can be impacted. This is vital because credit decisioning models must meet the dual criteria of:
- Explainability: model drivers are transparent to users and provide actionable conclusions for customers declined credit; and
- Generalization: models do not overfit the training data and perform well on new (production) data.
This article explains the importance of applying both monotonic and interaction constraints when training ML models in order to meet these criteria.
Transparency and Actionability
Many jurisdictions require lenders to explain how and why they declined an applicant for credit, stipulating lenders provide Adverse Action Codes that indicate the main reasons why they were declined. Correct explanations as to why a model’s prediction led a lender to decline credit makes the ML models transparent (there is no “black-box” vagueness as to the drivers of model prediction) and actionable (the customer’s declined credit has clear and tangible actions as to what steps they can take to improve their prospects of gaining credit). As a concrete example of explainability, if the feature in a model with the most negative impact to a declined loan applicant is “number of credit searches in the last six months” then the Adverse Action Code could be “number of credit searches in the last six months is too high.” This provides transparency of the main driver and clear action to the clients that to improve their creditworthiness they need to reduce their credit searches. Applicants can more easily become aware of the factors that are holding them back from better scores and improve their creditworthiness.
Transparency further assures the lenders that credit decisions are based on explainable and defendable features and do not use protected attributes such as gender, religion, or ethnicity.
Many explainability methods exist to help interpret drivers of complex models, but two have gained popularity:
- Local Interpretable Model-Agnostic Explanations (LIME)
- SHapley Additive exPlanation (SHAP)
LIME approximates complex ML models with a simpler local model that is easier to explain. Since LIME uses a proxy model focusing on the local impact of the features, it cannot be used for generating Adverse Action Codes, which must be specifically generated using the ML model adopted for credit decisioning (and not a proxy).
SHAP quantifies the contribution of each feature to a prediction made by an ML model (features with larger contributions to model prediction have a larger SHAP) thereby making model predictions transparent. But transparency using SHAP values doesn’t directly lead to the actionability necessary for use in Adverse Action Codes. In order to use SHAP values in deriving Adverse Action Codes, the following training constraints are needed:
- monotonic constraints, and
- interaction constraints.
Why are model constraints necessary?
To understand the reason why such model constraints are needed, it is useful to look at a SHAP dependence plot that shows the effect a single feature has on the predictions made by the model (the graph below has been produced off a Gradient Boosting Decision Tree, which has been trained on a credit risk dataset with the goal of estimating the probability of default of loan applicants).
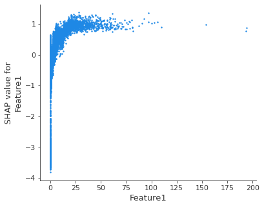
Figure 1 – SHAP dependence plot for Feature1
The first observation is that the pattern is non-monotonic: as the Feature1 values increase the creditworthiness improves, until it is predicted to deteriorate.
The first action needed is to enforce monotonic constraints, which impose model predictions to monotonically increase or decrease with respect to a feature when all other features are unchanged. In the example above, higher values of Feature1 would correspond to better creditworthiness. Departures from monotonicity (which can frequently occur when monotonic feature constraints are not applied) seldom represent a genuine pattern but instead can indicate an overfit of the in-sample relationship, thereby reducing model generalization.
Applying monotonic constraints is not enough for the SHAP values to be used to return Adverse Action Codes. In fact, features can be correlated to some degree: when features interact with each other in an ML model, the prediction cannot be expressed as the sum of features effects, because the effect of one feature depends on the value of some others.
The following SHAP dependence plot shows how the effect of Feature1 depends on the effect of Feature2: the interaction between Feature1 and Feature2 shows up as a distinct vertical pattern of colouring.
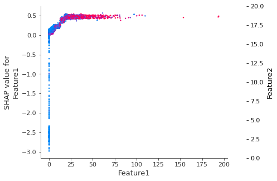
Figure 2 – SHAP dependence plot showing interaction between Feature1 and Feature2
The second action that needs to be taken is to enforce interaction constraints, which allow isolation of the behaviour by the model of each feature independent of every other feature, providing a clear picture of how an individual feature predicts risk: as a result, a model prediction corresponds to the sum of each individual effect.
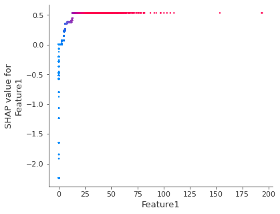
When both monotonic and interaction constraints are applied, SHAP values can be used to return Adverse Action Codes (some additional benefits include quicker training processes, better model generalization, and easier to interpret feature importance calculations). The following SHAP dependence plot shows the effect of Feature1 to the model prediction after both constraints have been applied: it can be noticed that there is a monotonic, one-to-one relationship between the feature values and the SHAP values.
Figure 3 – SHAP dependence plot of Feature1 after with monotonic and interaction constraints applied
Stay compliant with Provenir AI
Provenir AI adopts a careful approach to ML model development by ensuring overfit avoidance and providing fully transparent and actionable models, favouring consumers’ access to financing and, at the same time, enabling lenders to meet financial regulations.