TDS Mini: Want to Launch AI/ML? You Need a Data Detox
AI, banks vs fintechs, alternative data – how do all of these hot topics fit together?
Get the whole picture with a quick, insightful look at emerging technology and the future of fintech with Provenir’s Chief Product Officer, Carol Hamilton, and Finovate’s VP and Director of Fintech Strategy, Greg Palmer.
As Africa’s digital landscape continues to evolve, the use of data and AI in banking has become increasingly important in driving and enhancing financial inclusion across the continent. Today, as many as 57% of Africans and up to one-third of all adults globally lack any type of bank account, making it difficult to evaluate creditworthiness using traditional methods. This large population of unbanked individuals represents significant growth for innovative organizations.
How can fintechs and digital banks begin this journey to remove barriers to financial inclusion and expand their potential audiences? By combining data with the power of AI, financial service providers can leverage new insights to support financial inclusion while mitigating risk.
Our panel of experts will discuss how financial service providers are doing just that to redefine banking services and products that cater to the unique needs of the unbanked and underserved populations in Africa.
Topics include:
Understanding how simplified access to alternative and non-traditional data can reshape your business
How the current approach to determining risk profiles impacts the unbanked population and gaps using only traditional data leaves in determining credit risk
How alternative data and advanced analytics can catalyze financial inclusion while reducing risk and fraud
The role of alternative data in the larger picture of tech-enabled financial inclusion
Actionable steps you can take to incorporate alternative data into your decisioning
Infrastructure Talents are Some of the Challenges Finance Industry Faces in Adopting AI: Provenir
Bharath Vellore, Provenir’s General Manager of APAC, recently spoke to e27 about the increasing number of case studies for AI in the financial industry such as fraud identification, credit scoring and risk management. He also outlined key considerations organizations should consider to implement AI successfully.
Provenir to Start Supplying Quick Finans with AI Functionality
Provenir continues to meet the increasing demand for its AI-Powered Data and Decisioning Platform around the globe. This Payment Expert article discusses how Provenir is expanding its global partnerships network in Turkey by partnering with Quick Finans to quickly approve and onboard its new customers.
Quick Finans is one of the multiple international deals Provenir has signed, including DeltaPay, a BNPL provider in Africa aid focused on increasing the financial inclusion rates in Africa.
A Geek’s Guide to Machine Learning (AI), Risk Analytics and Decisioning
Introduction
Artificial Intelligence (AI), Machine Learning (ML) – whatever you want to call it, these buzzwords are appearing more and more throughout the business and social world. So what are they and what do they mean?
Despite the growing interest, AI/ML isn’t new at all. In fact, the models themselves have been around since the 1970s and ‘80s. In the financial sector, banks have been using ML to mitigate fraud and detect irregular buyer behaviors and patterns for the last decade or more.
Fraud is a growing concern and is costing the financial sector millions of dollars in losses each year. A 2015 research note from Barclays stated that the United States is responsible for 47 percent of the world’s card fraud despite accounting for only 24 percent of total worldwide card volume. A 2014 Federal Trade Commission report shows that credit cards and other consumer payment methods produced the greatest losses over other types of fraud.
One of the ways in which UK financial firms have tried to reduce fraud is with the implementation of the Chip and Pin system. It was seen as an effective means to prevent and reduce card fraud. But a research paper by Murdoch et al (2010) showed how fundamentally flawed Chip and Pin is.
As technology evolves, so do the cunning methods for perpetrating a fraudulent crime. Financial firms are now relying on sophisticated artificial intelligence software to evolve, adapt and learn in line with the behavior patterns of fraudsters in order to track, detect and prevent fraud far more quickly than traditional methods. The use of AI has also been implemented in industries outside financial services including insurance, retail and telecommunications.
Obviously, it is in the interest of the card issuer or bank to implement strategies to reduce the risk of fraud. Unfortunately, this often requires a compromise between expense and inconvenience to the merchant and the customer. Merchants are at far more risk than the end credit card user as they are ultimately responsible for incurring the cost of a fraudulent purchase and the potential loss of the customer resulting from the bad experience. Other costs to the merchant include direct fraud costs, cost of manual order review, cost of reviewing tools and cost of rejecting orders.
This Provenir report describes the use of AI tools in credit card fraud to mitigate risk. We will be looking at various AI detection methods including Artificial Neural Networks (ANN), Fuzzy Neural Networks (FNN), Bayesian Neural Networks (BNN) and Expert Systems.
An Overview of Fraud Prevention and Detection Techniques
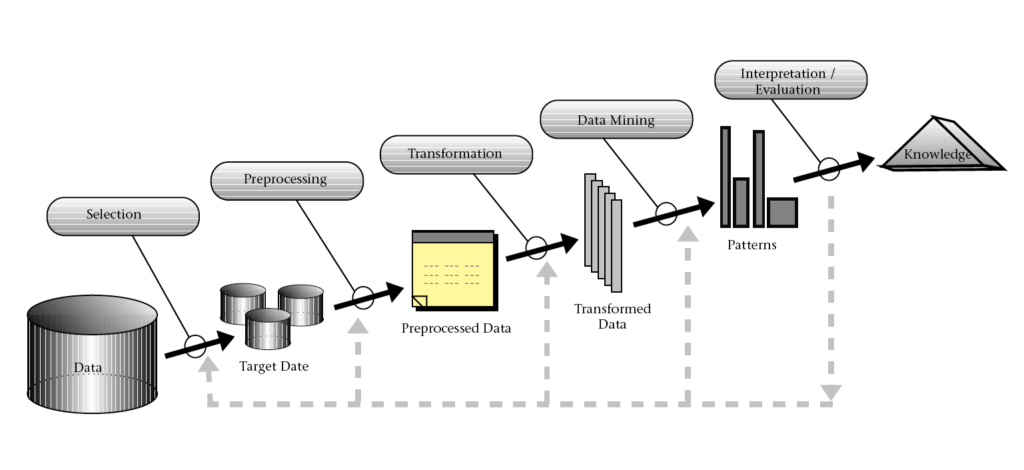
The modern information age is flooded with a rapidly growing and astonishingly huge amount of data. In the U.S alone, the total number of credit card transactions totaled 26.2 billion in 2012. The processing of these data sets by banks and credit card issuers requires complex statistical algorithms to extract the raw quantitative data.
An overview of the processes that compose Knowledge Discovery in Databases (KDD) (Source: Fayyad et al, 1996).
These systems work by comparing the observed and collected data with expected values. Expected values can be calculated in a number of ways. For example, a behavior model would look at the way a customer’s bank account has been used in the past, and any deviance from usual purchasing habits would return a suspicion score. This method works by flagging a transaction with a typical score, usually between 1 and 999. The higher the score, the more suspicious the transaction is likely to be, or, the more similarities it shares between other fraudulent values.
Typically, the measures taken to combat fraud can be distinguished into two categories – Prevention and Detection.
Fraud Prevention constitutes the necessary steps to prevent fraud from occurring in the first place, with various preventative methods used to deter fraudsters, such as MasterCard SecureCode and Verified by Visa.
Fraud Detection, the focus of this report, comes into play once fraud prevention fails. Detection consists of identifying and detecting the fraudulent activity as quickly as possible and implementing the necessary methods to block and prevent the card from being used by the perpetrator again. Issues arise when criminals adapt and change their tactics once they are aware that a prevention method is in place, therefore the need for more intelligent and sophisticated technology which ‘learns’ is essential for the detection of fraud.
The techniques used to detect fraud also fall into two primary classes – Statistical techniques (clustering, algorithms) and Artificial Intelligence (ANN, FNN, Data Mining). Both of these methods still involve mining through the available data and highlighting any anomalies (which can be defined by a set of rules) from the purchasing and transaction data of the customer. The difference is that where we used human analysts to manually search useable knowledge in the past, today we make use by machine learning.
Artificial Intelligence Models
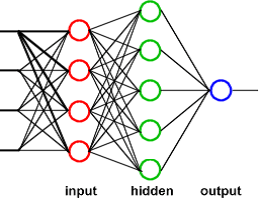
Artificial Neural Networks Also known as connectionism, parallel distributed processing, neuro-computing and machine learning algorithms, Artificial Neural Networks (ANNs) were first developed during the late 1980s and have since become a fundamental tool in combating fraud. ANNs work by imitating the way the human brain learns, using complex input, hidden, and output layers.
Diagram representing a feed-forward multilayer perceptron (the most common type of ANN). (Source: www. oscarkilo.net)
The input nodes retrieve information from an outside source (for credit card fraud detection, this would be the transactional data of a customer’s account) and the output nodes send the results from the neural networks back to the external source. The hidden nodes in-between the input and output nodes have no interaction with the external source and become more complex in their configuration and nature depending on the complexity of the problem at hand.
The various nodes in each layer of the neural network are connected by edges where each edge represents a particular weight between two connected nodes. (In the human brain, these are called synapses.) The information that the neural network learns through supervised or unsupervised learning is stored in these weights.
An example of the way neural networks learn is similar to the way children learn to recognize animals. After seeing a dog, the child can then generalize on various other breeds of dogs, categorizing and defining them as ‘dogs’ without having seen them before. An important feature of neural networks is that when they learn, they have the option to be supervised or unsupervised.
For unsupervised neural network learning, the system makes use of clustering, which groups patterns based on similarity. The two main unsupervised learning methods are Hebbian and Kohonen. Hebbian learning takes place by association, meaning that if two neurons which are on either side of a synapse are activated simultaneously, the strength of that synapse will be increased. Kohonen (also called Self-Organizing Maps) learning takes place by learning the categorization of the input space.
For supervised neural network learning (back-propagation), the correct output values for certain input data are determined before starting the algorithm, and the system then learns the function between the paired input and output nodes.
A user can train a neural network by running through examples of past data. The learning process occurs when the output data is compared to that of the ANN’s predicted output. The weights for each connection are then adjusted based on the exampled data, allowing the system to learn new patterns and behavior and improve accuracy without having to be taught or shown it.
Fuzzy Neural Networks
Fuzzy Neural Networks (FNNs) are a branch of hybrid intelligence systems which make use of fuzzy logic together with ANNs to detect fraudulent activity. The idea was first developed and proposed by Zadeh and has since been used and implemented successfully in a variety of industries. The core framework for fuzzy logic is to provide an accurate method for describing human perceptions. Some experts believe that the use of fuzzy rules can provide a more natural estimate as to the amount of deviation from the normal.
FNNs, like Expert Systems, make use of IF-THEN-ELSE statements and heuristic rules to handle uncertainty in applications, resulting in better approximate reasoning without the need for analytical precision. The use of traditional IF-THEN-ELSE statements and heuristic rules (see Expert Systems below) has been controversial, and therefore has not been as widely implemented as some of the other AI fraud detection systems.
Expert Systems
Expert Systems saw increased usability and growth during the 1980s with the expansion of computer processing power, programming and AI. It was used in credit card fraud detection by using a rule-based system which proved to be fairly popular when no other intelligent systems were around. These systems were used to imitate and replicate the knowledge of an ‘expert’ person and can be defined into two classes – facts and heuristic.
Facts are classified as a quantity of information, such as the credit card transaction history or an individual’s credit rating.
Heuristic is where a person of ‘expert’ knowledge defines a set of rules that they would usually follow by protocol as a result of their ‘expert’ experience, education, observation and training.
Expert systems work by taking this human knowledge and transferring it into a logical language that a computer can understand and follow in order to solve a problem. A fundamental part of expert systems is their extensive database of stored rules which are defined by a typical IF-THEN-ELSE format. For example, a rule based system using IF-THEN-ELSE may look like the following:
IF the amount of purchase is greater (>) than $1000 and the card acceptance authorization is through ‘eBay’, THEN raise a suspicion score and require further verification, ELSE approve transaction.
Limitations of Expert Systems however are that they require considerable storage space and rely heavily on extensive programming of expert human knowledge in order to make decisions. Some experts b
Bayesian Neural Networks
These types of networks take a slightly different approach to the general guidelines and rules of learning that are commonly seen in ANNs and FNNs. Typically, Bayesian Neural Networks use Naive Bayesian Classifiers, a simple method of classification, to classify transaction activity.
Bayesian learning can be trained very efficiently in a supervised learning setting and uses probability to represent uncertainty about relationships that have been learnt as opposed to variations on maximum likelihood estimation. Where neural networks try to find a set of weights for each node (process of learning) to best fit the data inputted, Bayesian learning makes prior predictions by means of probability distribution over the network weights as to what the true relationship might be. One study looked at the comparison of using both ANNs and Bayesian Belief Network algorithms in fraud detection, and found that the use of Bayesian Neural Networks, although slower, were in fact more accurate than the use of ANNs alone.
In fact, many believe the use of Bayesian methods to be highly effective in real world data sets as they offer better predictive accuracy. This is supported by research which concluded that the use of Bayesian Neural Networks were far superior and accurate in detecting credit card transactional fraud than Naive Bayesian Classifier.
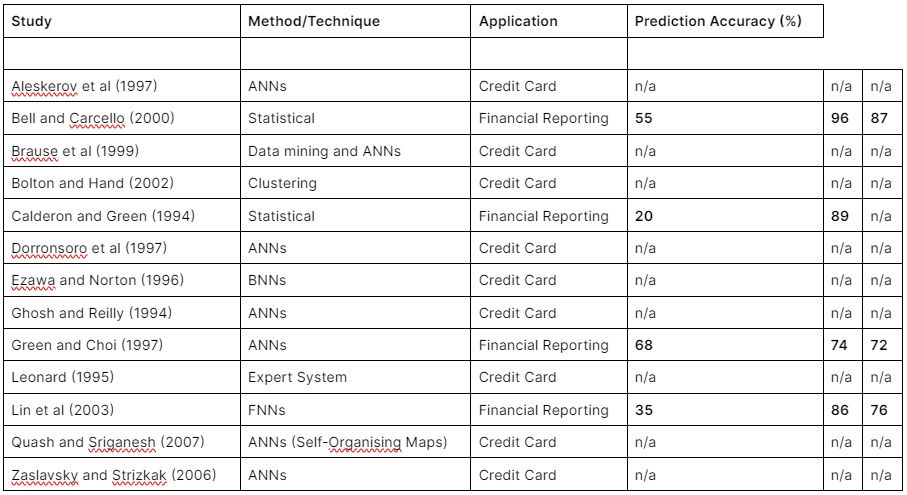
The Data
The following table compares the research findings to highlight which combination of models provides the highest prediction accuracy.
Summary of the most notable investigations into the use of Artificial Intelligence at mitigating fraud.
The greatest challenge when talking about artificial intelligence/machine learning is actually in understanding what data sets we are looking at, and what model/combination of models to apply. Amazon’s Machine Learning offering is one example of an automated process which analyses the data and automatically selects the best model to use in the scenario. Other big players who have similar offerings are IBM Watson, Google and Microsoft.
Conclusion
Provenir’s clients are continually looking at new and innovative ways to improve their risk decisioning. Traditional banks offering consumer, SME and commercial loans and credit, auto lenders, payment providers and fintech companies are using Provenir technology to help them make faster and better decisions about potential fraud. Integrating artificial intelligence/machine learning capabilities into the risk decisioning process can increase the organization’s ability to accurately assess the level of risk in order to detect and prevent fraud.
Provenir provides model integration adaptors for machine learning models, including Amazon Machine Learning (AML) that can automatically listen for and label business-defined events, calculate attributes and update machine learning models. By combining Provenir technology with machine learning, organizations can increase both the efficiency and predictive accuracy of their risk decisioning.
Deploy Machine Learning in Your Financial Institution Rapidly
How to achieve explainability and transparency with complex ML models
An ever-increasing number of lenders are adopting advanced Machine Learning (ML) models to inform credit decisions. ML models (such as Random Forest, XGBoost, LightGBM and Neural Networks) are more predictive and accurate than the industry standard Logistic Regression, as they capture highly complex nonlinear relationships. However, without careful configuration during training, both model explainability and generalization can be impacted. This is vital because credit decisioning models must meet the dual criteria of:
Explainability
model drivers are transparent to users and provide actionable conclusions for customers declined credit; and
Generalization
models do not overfit the training data and perform well on new (production) data.
This article explains the importance of applying both monotonic and interaction constraints when training ML models in order to meet these criteria.
Transparency and Actionability
Many jurisdictions require lenders to explain how and why they declined an applicant for credit, stipulating lenders provide Adverse Action Codes that indicate the main reasons why they were declined. Correct explanations as to why a model’s prediction led a lender to decline credit makes the ML models transparent (there is no “black-box” vagueness as to the drivers of model prediction) and actionable (the customer’s declined credit has clear and tangible actions as to what steps they can take to improve their prospects of gaining credit). As a concrete example of explainability, if the feature in a model with the most negative impact to a declined loan applicant is “number of credit searches in the last six months” then the Adverse Action Code could be “number of credit searches in the last six months is too high.” This provides transparency of the main driver and clear action to the clients that to improve their creditworthiness they need to reduce their credit searches. Applicants can more easily become aware of the factors that are holding them back from better scores and improve their creditworthiness.
Transparency further assures the lenders that credit decisions are based on explainable and defendable features and do not use protected attributes such as gender, religion, or ethnicity.
Many explainability methods exist to help interpret drivers of complex models, but two have gained popularity:
Local Interpretable Model-Agnostic Explanations (LIME)
SHapley Additive exPlanation (SHAP)
Why are model constraints necessary?
To understand the reason why such model constraints are needed, it is useful to look at a SHAP dependence plot that shows the effect a single feature has on the predictions made by the model (the graph below has been produced off a Gradient Boosting Decision Tree, which has been trained on a credit risk dataset with the goal of estimating the probability of default of loan applicants).
Figure 1 – SHAP dependence plot for Feature1
The first observation is that the pattern is non-monotonic: as the Feature1 values increase the creditworthiness improves, until it is predicted to deteriorate.
The first action needed is to enforce monotonic constraints, which impose model predictions to monotonically increase or decrease with respect to a feature when all other features are unchanged. In the example above, higher values of Feature1 would correspond to better creditworthiness. Departures from monotonicity (which can frequently occur when monotonic feature constraints are not applied) seldom represent a genuine pattern but instead can indicate an overfit of the in-sample relationship, thereby reducing model generalization.
Applying monotonic constraints is not enough for the SHAP values to be used to return Adverse Action Codes. In fact, features can be correlated to some degree: when features interact with each other in an ML model, the prediction cannot be expressed as the sum of features effects, because the effect of one feature depends on the value of some others.
The following SHAP dependence plot shows how the effect of Feature1 depends on the effect of Feature2: the interaction between Feature1 and Feature2 shows up as a distinct vertical pattern of colouring.
Figure 2 – SHAP dependence plot showing interaction between Feature1 and Feature2
The second action that needs to be taken is to enforce interaction constraints, which allow isolation of the behaviour by the model of each feature independent of every other feature, providing a clear picture of how an individual feature predicts risk: as a result, a model prediction corresponds to the sum of each individual effect.
When both monotonic and interaction constraints are applied, SHAP values can be used to return Adverse Action Codes (some additional benefits include quicker training processes, better model generalization, and easier to interpret feature importance calculations). The following SHAP dependence plot shows the effect of Feature1 to the model prediction after both constraints have been applied: it can be noticed that there is a monotonic, one-to-one relationship between the feature values and the SHAP values.
Figure 3 – SHAP dependence plot of Feature1 after with monotonic and interaction constraints applied
Stay compliant with Provenir AI
Provenir AI adopts a careful approach to ML model development by ensuring overfit avoidance and providing fully transparent and actionable models, favouring consumers’ access to financing and, at the same time, enabling lenders to meet financial regulations.
Want to learn more about how Provenir AI enables transparency and actionability?
Risk decisioning or risk assessment has traditionally been a detail intensive task with someone sifting through information or data to make informed decisions based on the risk profiles. Using AI, organizations can process a larger volume and variety of data to spot patterns, gain better insight into their customers and identify potential risks at scale.
Listen to this podcast on BFM 89.9, The Business Station, as Bharath Vellore, Provenir’s General Manager for the APAC region, shares insights into how AI can help improve the customer experience and financial inclusion.
Make Smarter Decisions Faster with a Risk Decisioning Ecosystem
In today’s digital-first world you know that you need to make smarter decisions that keep you ahead of risks without sacrificing your industry-leading consumer experience. You also know that saying ‘yes’ to the right people in real-time takes more than a simple decisioning tool.
To innovate, thrive, and disrupt in an increasingly competitive market you need to be able to get to market quickly, learn from your data, and iterate—all on your timeline. You need technology that empowers you to create a risk decisioning ecosystem where data, decisioning, and analytics all work together to drive business growth and agility.
Introducing the Provenir AI-Powered Risk Decisioning Platform
In our latest eBook we explore the technology that you need to supercharge your decisioning and how combining these tech features into one cohesive ecosystem will set you apart from your competitors.
Download the eBook now to learn:
how simplified integration and access to data on-demand from 600+ sources, including credit risk, fraud, open banking and alternative data, makes your risk decisioning more accurate
why a single UI with no-code UX is vital to business agility and speed to market
how real-time views of decisioning, performance and third-party data empower you to innovate faster
Ready to get the all-inclusive credit risk decisioning experience you’ve been waiting for?
The Ultimate Guide to Decision Engines
What is a decision engine and how does it help your business processes?
Serving Gen Z Demands Alternative Data and AI to Foster More Inclusive Credit Decisioning
The most significant transfer of wealth in U.S. history is underway as Baby Boomers begin transitioning assets to younger generations. Over $70 trillion is in motion, underscoring the need for financial institutions to fully invest themselves in understanding the needs and preferences of younger consumers.
In this article, Kim Minor, SVP of Marketing for Provenir, shares insights on how alternative data and AI can help financial services providers reengineer their processes to be more inclusive of these younger clients with low or no financial history.
Machine Learning – Revolutionizing Financial Risk Analysis and Decision-Making
While the concept of Machine Learning (ML) may conjure up images of a dystopian future where machines have taken over the world, much like Skynet in the Terminator movies, the reality is quite different. While Skynet may have been a malicious and all-powerful AI system, Machine Learning is simply a tool that can help us better understand and leverage data. So, while Skynet may have been the ultimate villain, Machine Learning is more like the trusty sidekick that helps us save the day.
Here’s how ML is rapidly becoming a game-changer in the field of financial risk analysis and decision-making:
The Power of Data
Machine learning enables businesses to gather and analyze data faster, thereby arriving at insights quicker. This is because the software program uses pattern recognition to build automatic analytical models, eliminating the need for human intervention.
Dynamic Fraud Detection
Machine learning algorithms can learn from a customer’s previous transactions and use them to identify patterns of behavior, allowing for dynamic fraud detection. This eliminates the inconvenience of manual validation processes while also increasing fraud detection rates, saving considerable costs.
Huge Cost Savings
According toanalysis firm Oakhall, global financial services firms could save $12 billion annually through machine learning fraud management. This underscores the tremendous potential for risk analysis and decision-making with machine learning.
Harnessing Machine Learning for Predictive Analytics
To fully benefit from the predictive analytics power of machine learning, financial institutions need a fast, simple way to connect their machine learning application to their credit and lending decisioning processes.
Machine learning is revolutionizing the financial risk analysis and decision-making process. Its power lies in its ability to gather andanalyze data faster, dynamically detect fraud, and save costs. By harnessing its predictive analytics capabilities, businesses can unlock its full potential for risk analysis.
Deploy Machine Learning in Your Financial Institution Rapidly